Каждый раз когда в командную строку Linux Shell вводится команда для выполнению, bash выполняет множество преобразований над текстом команды перед ее выполнением. Ранее мы сталкивались с подстановками файлов по шаблонам, но детально не разобрали как оно устроено. А оно является частью механизма развертывания. Например, когда в рабочей директории два файла test1.txt и test2.txt, мы можем выбрать их с помощью подстановки по шаблону «t*.txt». Например, если мы желаем их удалить, мы воспользуемся командой rm.
Программа rm в качестве аргументов ожидает имена файлов к удалению, а мы передали ей шаблон. На самом деле программа не видит наш шаблон. В процессе развертывания строки, наша команда была преобразована с перечислением всех файлов.
Программе rm, как и остальным, нет необходимости в поддержке шаблонов имен файлов, чтобы они работали. Выборка файлов происходит до выполнения программы. А программа выполняет лишь свой функционал Это позволяет экономить значительные ресурсы при разработке программ 🙂
Развертывание строк не ограничивается подстановкой имен файлов по шаблонам. Основной принцип в том, что при вводе какой-то инструкции с подстановками для выполнения, она преобразуется в другую, где все подстановки развернуты.
Чтобы увидеть конечный вид команды, которая выполняется после всех развертываний, нам понадобится команда, которая выводит все переданные аргументы. Воспользуемся командой echo. Она выводит все ее аргументы в стандартный вывод, который при необходимости можно перенаправить в файл.
|
|
[mikhail@localhost test]$ echo Testing echo Testing echo [mikhail@localhost test]$ |
При помощи команды echo и перенаправления вывода создадим два файла test1.txt и test2.txt с каким нибудь текстом.
|
|
[mikhail@localhost test]$ echo File 1 text > test1.txt [mikhail@localhost test]$ echo File 2 text > test2.txt [mikhail@localhost test]$ ls bin.txt test1.txt test2.txt test.txt usr-sorted.txt usr.txt [mikhail@localhost test]$ |
С помощью echo можно записывать информацию в файл. Команда echo считывает выводимые данные из аргументов команды, а не стандартного ввода, как мы это делали ранее с помощью программы cat. Аргументы любой команды являются частью вводимой инструкции, поэтому к ним применимо развертывание. Посмотрим как оно работает при помощи команды echo на подстановках имени файлов по шаблонам.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
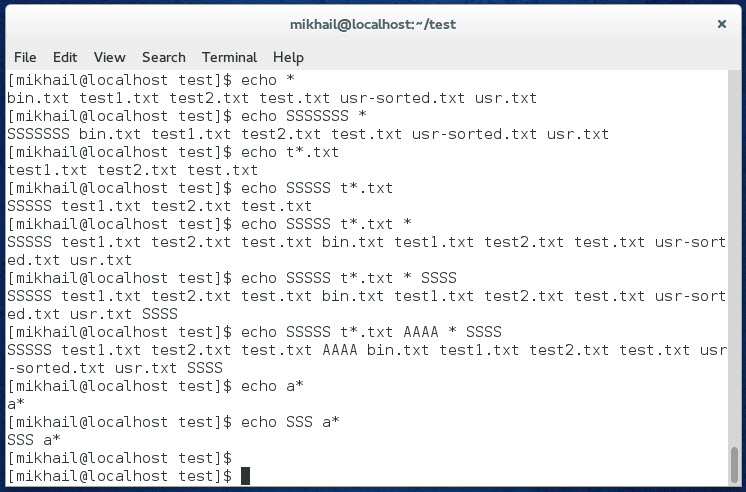
[mikhail@localhost test]$ echo * bin.txt test1.txt test2.txt test.txt usr-sorted.txt usr.txt [mikhail@localhost test]$ echo SSSSSSS * SSSSSSS bin.txt test1.txt test2.txt test.txt usr-sorted.txt usr.txt [mikhail@localhost test]$ echo t*.txt test1.txt test2.txt test.txt [mikhail@localhost test]$ echo SSSSS t*.txt SSSSS test1.txt test2.txt test.txt [mikhail@localhost test]$ echo SSSSS t*.txt * SSSSS test1.txt test2.txt test.txt bin.txt test1.txt test2.txt test.txt usr-sorted.txt usr.txt [mikhail@localhost test]$ echo SSSSS t*.txt * SSSS SSSSS test1.txt test2.txt test.txt bin.txt test1.txt test2.txt test.txt usr-sorted.txt usr.txt SSSS [mikhail@localhost test]$ echo SSSSS t*.txt AAAA * SSSS SSSSS test1.txt test2.txt test.txt AAAA bin.txt test1.txt test2.txt test.txt usr-sorted.txt usr.txt SSSS [mikhail@localhost test]$ echo a* a* [mikhail@localhost test]$ echo SSS a* SSS a* [mikhail@localhost test]$ |
Каждая подстановка, в которой была произведена выборка файлов, замена последовательностью имен файлов. В последних двух примерах мы выполняли подстановку по шаблону «a*». Данному шаблону не соответствует ни одно имя файла в рабочей директории, потому подстановка развернута не была и осталась в неизменном виде.
Помимо подстановке имен файлов по шаблонам, существуют и иные развертывания строк.
Пользовательская директория
Нам уже известны специальные ярлыки пользовательских директорий. Они работают на этапе развертывания строк. Символ “~” (тильда) при развертывании заменяется на собственную домашнюю директорию. А если за ним следует имя учетной записи пользователя, тогда вся последовательность, начиная от символа «~» и заканчивая именем пользователя, заменяется на домашнюю директорию данного пользователя.
|
|
[mikhail@localhost test]$ echo ~ /home/mikhail [mikhail@localhost test]$ echo ~mikhail /home/mikhail [mikhail@localhost test]$ echo ~root /root [mikhail@localhost test]$ |
Арифметические операции
Linux Shell при развертывании вычисляет значения арифметических выражений. Командную строку можно использовать как калькулятор 🙂
Чтобы значение было вычислено, арифметическое выражение необходимо обернуть в двойные круглые скобки и поставить перед ними символ «$» (знак доллара).
|
|
[mikhail@localhost test]$ echo $((2+2)) 4 [mikhail@localhost test]$ |
Допускается использовать лишь целые числа. Вещественные числа (дроби) не поддерживаются 🙁 Пробелы в выражениях игнорируются, поэтому их можно использовать в качестве произвольных разделителей для удобства чтения. Выражения могут быть вложенными.
|
|
[mikhail@localhost test]$ echo $(($((5**2)) * 3)) 75 [mikhail@localhost test]$ |
В данном примере во вложенным арифметическом выражении число 5 возводится в квадрат (2 степень), затем результат умножается на 3.
Для группировки вложенных выражений можно использовать круглые скобки. Тогда предыдущий пример будет короче и лучше читаем.
|
|
[mikhail@localhost test]$ echo $(((5**2) * 3)) 75 [mikhail@localhost test]$ |
Возможно также целочисленное деление чисел и извлечение остатка. Попробуем разделить 5 жестких дисков на два компьютера, так чтобы каждый получил поровну.
|
|
[mikhail@localhost test]$ echo Rezultat $((5/2)), ostatok $((5%2)) Rezultat 2, ostatok 1 [mikhail@localhost test]$ |
Один диск остался в запасе 😉 Как мы заметили, развертывание выражений работает точно также как и развертывание подстановок имени файла по шаблону — происходит замена выражения на результат. Его можно использовать с любыми командами.
Попробуем записать список всех файлов в рабочей директории в файл, имя которого начинается со слова «test», после чего идет число равное результату умножения 25 на 132 (сколько будет? :)) и заканчивается строкой «.txt».
|
|
[mikhail@localhost test]$ echo * > test$((25 * 132)).txt [mikhail@localhost test]$ ls bin.txt test1.txt test2.txt test3300.txt test.txt usr-sorted.txt usr.txt [mikhail@localhost test]$ cat test$((25 * 132)).txt bin.txt test1.txt test2.txt test.txt usr-sorted.txt usr.txt [mikhail@localhost test]$ |
Развертывание последовательностей и комбинации
При помощи последовательностей можно создать множество различных комбинаций строк по заданному шаблону. Последовательность задается либо перечислением строк, либо интервалом целых чисел или символов.
Для развертывания последовательности, состоящей из интервала целых чисел или символов, в фигурных скобках указывают границы интервала, разделенные двумя точками («..»). Интервал может быть указан как в возрастающем порядке, так и в убывающем.
|
|
[mikhail@localhost test]$ echo {b..e} b c d e [mikhail@localhost test]$ echo {e..b} e d c b [mikhail@localhost test]$ echo {4..15} 4 5 6 7 8 9 10 11 12 13 14 15 [mikhail@localhost test]$ echo {04..15} 04 05 06 07 08 09 10 11 12 13 14 15 [mikhail@localhost test]$ echo {15..10} 15 14 13 12 11 10 [mikhail@localhost test]$ |
Если последовательность состоит из списка строк, то их разделяют запятыми и помещают в фигурные скобки.
|
|
[mikhail@localhost test]$ echo {aaa,bb,fff,cccccc} aaa bb fff cccccc [mikhail@localhost test]$ |
Сами строки внутри последовательности тоже развертываются.
|
|
[mikhail@localhost test]$ echo {t*,{3..5},fff$((2+5))} test1.txt test2.txt test3300.txt test.txt 3 4 5 fff7 [mikhail@localhost test]$ |
Последовательность можно окружить текстом, тогда при ее разворачивании у элементов последовательности тоже появится окружающий текст.
|
|
[mikhail@localhost test]$ echo file{1..4}.txt file1.txt file2.txt file3.txt file4.txt [mikhail@localhost test]$ echo file{a,dd,bb}.txt filea.txt filedd.txt filebb.txt [mikhail@localhost test]$ |
С учетом того, что к строкам внутри последовательности тоже применяется развертывание строк, возможно использование вложенных последовательностей.
|
|
[mikhail@localhost test]$ echo {aaa{b,ff},bb{1..9},fff{d..g},c} aaab aaaff bb1 bb2 bb3 bb4 bb5 bb6 bb7 bb8 bb9 fffd fffe ffff fffg c [mikhail@localhost test]$ |
К окружающему тексту тоже применяется развертывание строк.
|
|
[mikhail@localhost test]$ echo a$((2+8))aaa{aa,dddd}ssss a10aaaaassss a10aaaddddssss [mikhail@localhost test]$ |
А значит возможно составление сложных комбинаций их нескольких последовательностей.
|
|
[mikhail@localhost test]$ echo a{1..3}d{fff,s{ee,a}}.txt a1dfff.txt a1dsee.txt a1dsa.txt a2dfff.txt a2dsee.txt a2dsa.txt a3dfff.txt a3dsee.txt a3dsa.txt [mikhail@localhost test]$ |
Это очень удобно и позволяет сэкономить много времени. Ранее мы пытались создать дерево директорий для сортировки фотографий по датам, которое выглядело как photo/год/месяц/день. Тогда мы создали всего две директории (не считая родительских) photo/2014/01/10 и photo/2010/12/05. Сейчас мы создадим директории для всевозможных дат за 2013-2015 годы. Чтобы это выполнить нам вполне достаточно перечислить их имена (относительные пути), а родительские директории программа mkdir создаст автоматически. Но в году 365 дней, значит нужно перечислить все $((3*365)) 😉 директорий.
Попробуем решить задачу с помощью последовательностей. Первый шаблон, который приходит в голову «photo/{2013..2015}/{01..12}/{01..31}». Но тогда мы получим $((3*12*31)) директорий, что явно больше чем наши $((3*365)) дней в этих годах 🙂 Наверное, нужно учесть, разное количество дней в каждом месяце. Нам поможет вложенная последовательность. В итоге мы получим «photo/{2013..2015}/{{01,03,05,07,08,10,12}/{01..31},{04,06,09,11}/{01..30},02/{01..28}}». Перед тем, как что-то создавать, испытаем наш шаблон при помощи команды echo. Так как результат будет слишком длинным, перенаправим вывод в программу для чтения текста less и пролистаем там.
|
|
[mikhail@localhost test]$ echo photo/{2013..2015}/{{01,03,05,07,08,10,12}/{01..31},{04,06,09,11}/{01..30},02/{01..28}} | less [mikhail@localhost test]$ |
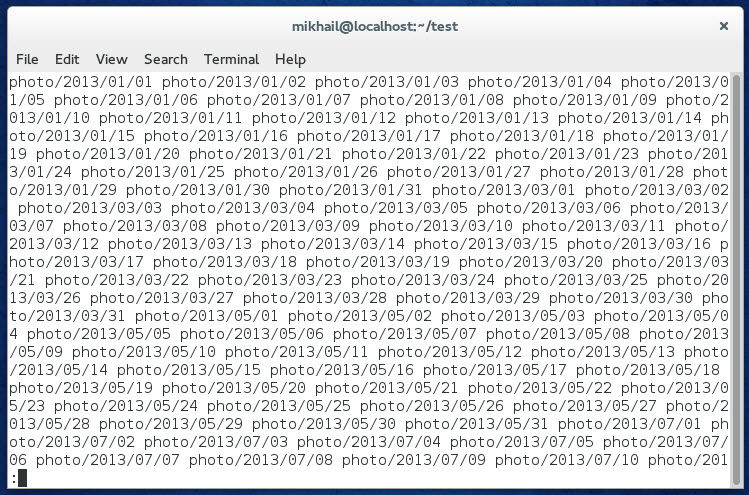
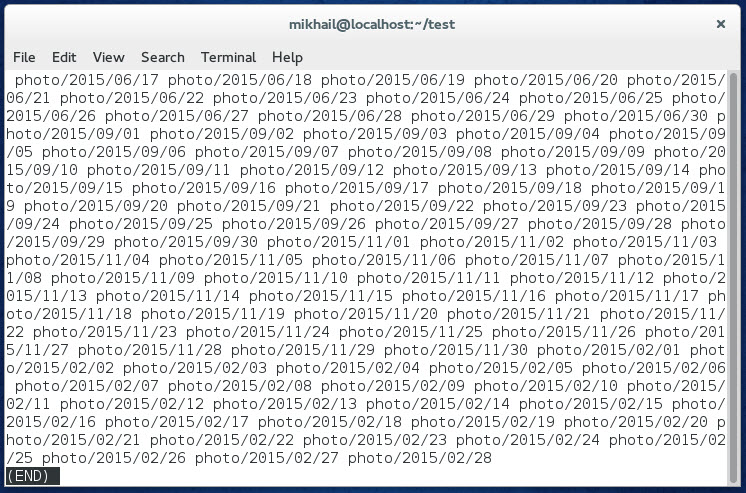
Выглядит как мы и ожидали. Значит теперь создадим все папки, заменив echo на mkdir с ключом -p.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
[mikhail@localhost test]$ mkdir -p photo/{2013..2015}/{{01,03,05,07,08,10,12}/{01..31},{04,06,09,11}/{01..30},02/{01..28}} [mikhail@localhost test]$ ls photo 2013 2014 2015 [mikhail@localhost test]$ ls photo/2013 01 02 03 04 05 06 07 08 09 10 11 12 [mikhail@localhost test]$ ls photo/2014 01 02 03 04 05 06 07 08 09 10 11 12 [mikhail@localhost test]$ ls photo/2013/01 01 03 05 07 09 11 13 15 17 19 21 23 25 27 29 31 02 04 06 08 10 12 14 16 18 20 22 24 26 28 30 [mikhail@localhost test]$ ls photo/2013/02 01 03 05 07 09 11 13 15 17 19 21 23 25 27 02 04 06 08 10 12 14 16 18 20 22 24 26 28 [mikhail@localhost test]$ ls photo/2013/03 01 03 05 07 09 11 13 15 17 19 21 23 25 27 29 31 02 04 06 08 10 12 14 16 18 20 22 24 26 28 30 [mikhail@localhost test]$ ls photo/2013/04 01 03 05 07 09 11 13 15 17 19 21 23 25 27 29 02 04 06 08 10 12 14 16 18 20 22 24 26 28 30 [mikhail@localhost test]$ |
Как видим, все прошло отлично. Столь сложная на первый взгляд задача была решена столько простой командой. Если кто-то не уверен, то может пробежать по всему созданному дереву директорий и проверить его вручную 🙂
Значения переменных
Переменные в Linux Shell позволяют записывать данные в области памяти, присваивая им имена, которые в дальнейшем можно использовать. При работе с командной строкой они не настолько полезны, как при разработке Shell скриптов, поэтому сейчас лишь поверхностно рассмотрим их.
Для развертывания значения переменной перед её именем ставится символ «$» (знак доллара). Например, мы желаем узнать значение переменной «USER». Выведем его с помощью команды echo.
|
|
[mikhail@localhost test]$ echo $USER mikhail [mikhail@localhost test]$ |
Для вывода списка всех переменных окружения и их значений можно воспользоваться командой printenv.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
[mikhail@localhost test]$ printenv XDG_VTNR=1 XDG_SESSION_ID=1 HOSTNAME=localhost.localdomain IMSETTINGS_INTEGRATE_DESKTOP=yes GPG_AGENT_INFO=/run/user/1000/keyring-QNL84t/gpg:0:1 VTE_VERSION=3409 TERM=xterm-256color SHELL=/bin/bash XDG_MENU_PREFIX=gnome- HISTSIZE=1000 GJS_DEBUG_OUTPUT=stderr WINDOWID=25166226 GNOME_KEYRING_CONTROL=/run/user/1000/keyring-QNL84t GJS_DEBUG_TOPICS=JS ERROR;JS LOG IMSETTINGS_MODULE=none USER=mikhail LS_COLORS=rs=0:di=38;5;27:ln=38;5;51:mh=44;38;5;15:pi=40;38;5;11:so=38;5;13:do=38;5;5:bd=48;5;232;38;5;11:cd=48;5;232;38;5;3:or=48;5;232;38;5;9:mi=05;48;5;232;38;5;15:su=48;5;196;38;5;15:sg=48;5;11;38;5;16:ca=48;5;196;38;5;226:tw=48;5;10;38;5;16:ow=48;5;10;38;5;21:st=48;5;21;38;5;15:ex=38;5;34:*.tar=38;5;9:*.tgz=38;5;9:*.arc=38;5;9:*.arj=38;5;9:*.taz=38;5;9:*.lha=38;5;9:*.lzh=38;5;9:*.lzma=38;5;9:*.tlz=38;5;9:*.txz=38;5;9:*.tzo=38;5;9:*.t7z=38;5;9:*.zip=38;5;9:*.z=38;5;9:*.Z=38;5;9:*.dz=38;5;9:*.gz=38;5;9:*.lrz=38;5;9:*.lz=38;5;9:*.lzo=38;5;9:*.xz=38;5;9:*.bz2=38;5;9:*.bz=38;5;9:*.tbz=38;5;9:*.tbz2=38;5;9:*.tz=38;5;9:*.deb=38;5;9:*.rpm=38;5;9:*.jar=38;5;9:*.war=38;5;9:*.ear=38;5;9:*.sar=38;5;9:*.rar=38;5;9:*.alz=38;5;9:*.ace=38;5;9:*.zoo=38;5;9:*.cpio=38;5;9:*.7z=38;5;9:*.rz=38;5;9:*.cab=38;5;9:*.jpg=38;5;13:*.jpeg=38;5;13:*.gif=38;5;13:*.bmp=38;5;13:*.pbm=38;5;13:*.pgm=38;5;13:*.ppm=38;5;13:*.tga=38;5;13:*.xbm=38;5;13:*.xpm=38;5;13:*.tif=38;5;13:*.tiff=38;5;13:*.png=38;5;13:*.svg=38;5;13:*.svgz=38;5;13:*.mng=38;5;13:*.pcx=38;5;13:*.mov=38;5;13:*.mpg=38;5;13:*.mpeg=38;5;13:*.m2v=38;5;13:*.mkv=38;5;13:*.ogm=38;5;13:*.mp4=38;5;13:*.m4v=38;5;13:*.mp4v=38;5;13:*.vob=38;5;13:*.qt=38;5;13:*.nuv=38;5;13:*.wmv=38;5;13:*.asf=38;5;13:*.rm=38;5;13:*.rmvb=38;5;13:*.flc=38;5;13:*.avi=38;5;13:*.fli=38;5;13:*.flv=38;5;13:*.gl=38;5;13:*.dl=38;5;13:*.xcf=38;5;13:*.xwd=38;5;13:*.yuv=38;5;13:*.cgm=38;5;13:*.emf=38;5;13:*.axv=38;5;13:*.anx=38;5;13:*.ogv=38;5;13:*.ogx=38;5;13:*.aac=38;5;45:*.au=38;5;45:*.flac=38;5;45:*.mid=38;5;45:*.midi=38;5;45:*.mka=38;5;45:*.mp3=38;5;45:*.mpc=38;5;45:*.ogg=38;5;45:*.ra=38;5;45:*.wav=38;5;45:*.axa=38;5;45:*.oga=38;5;45:*.spx=38;5;45:*.xspf=38;5;45: SSH_AUTH_SOCK=/run/user/1000/keyring-QNL84t/ssh SESSION_MANAGER=local/unix:@/tmp/.ICE-unix/1240,unix/unix:/tmp/.ICE-unix/1240 USERNAME=mikhail PATH=/usr/local/bin:/usr/bin:/bin:/usr/local/sbin:/usr/sbin:/home/mikhail/.local/bin:/home/mikhail/bin MAIL=/var/spool/mail/mikhail DESKTOP_SESSION=gnome QT_IM_MODULE=ibus PWD=/home/mikhail/test XMODIFIERS=@im=ibus GNOME_KEYRING_PID=1236 LANG=en_US.utf8 GDM_LANG=en_US.utf8 GDMSESSION=gnome HISTCONTROL=ignoredups XDG_SEAT=seat0 HOME=/home/mikhail SHLVL=2 GNOME_DESKTOP_SESSION_ID=this-is-deprecated LOGNAME=mikhail DBUS_SESSION_BUS_ADDRESS=unix:abstract=/tmp/dbus-GFq7MYXuEF,guid=2967dcfefd00586db9916b58541820a3 LESSOPEN=||/usr/bin/lesspipe.sh %s WINDOWPATH=1 XDG_RUNTIME_DIR=/run/user/1000 DISPLAY=:0 COLORTERM=gnome-terminal XAUTHORITY=/run/gdm/auth-for-mikhail-8O9TTd/database _=/usr/bin/printenv OLDPWD=/home/mikhail [mikhail@localhost test]$ |
Неустановленная (несуществующая) переменная при развертывании подменяется пустой строкой.
|
|
[mikhail@localhost test]$ echo $TEST [mikhail@localhost test]$ echo DEFINED is $USER and UNKNOWN is $TEST DEFINED is mikhail and UNKNOWN is [mikhail@localhost test]$ |
Чтобы задать значение переменной нужно указать имя переменной, после этого поставить символ «=» (знак равно) и указать значение переменной. Между именем переменной и символом «=» не должно быть пробелов. Зададим значение переменной «TEST».
|
|
[mikhail@localhost test]$ TEST=SSSS [mikhail@localhost test]$ echo $TEST SSSS [mikhail@localhost test]$ echo Test is $TEST Test is SSSS [mikhail@localhost test]$ |
Но, если мы попытаемся вывести список переменных при помощи команды printenv, то нашей переменной «TEST» там не будет.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
[mikhail@localhost test]$ printenv XDG_VTNR=1 XDG_SESSION_ID=1 HOSTNAME=localhost.localdomain IMSETTINGS_INTEGRATE_DESKTOP=yes GPG_AGENT_INFO=/run/user/1000/keyring-QNL84t/gpg:0:1 VTE_VERSION=3409 TERM=xterm-256color SHELL=/bin/bash XDG_MENU_PREFIX=gnome- HISTSIZE=1000 GJS_DEBUG_OUTPUT=stderr WINDOWID=25166226 OLDPWD=/home/mikhail GNOME_KEYRING_CONTROL=/run/user/1000/keyring-QNL84t GJS_DEBUG_TOPICS=JS ERROR;JS LOG IMSETTINGS_MODULE=none USER=mikhail LS_COLORS=rs=0:di=38;5;27:ln=38;5;51:mh=44;38;5;15:pi=40;38;5;11:so=38;5;13:do=38;5;5:bd=48;5;232;38;5;11:cd=48;5;232;38;5;3:or=48;5;232;38;5;9:mi=05;48;5;232;38;5;15:su=48;5;196;38;5;15:sg=48;5;11;38;5;16:ca=48;5;196;38;5;226:tw=48;5;10;38;5;16:ow=48;5;10;38;5;21:st=48;5;21;38;5;15:ex=38;5;34:*.tar=38;5;9:*.tgz=38;5;9:*.arc=38;5;9:*.arj=38;5;9:*.taz=38;5;9:*.lha=38;5;9:*.lzh=38;5;9:*.lzma=38;5;9:*.tlz=38;5;9:*.txz=38;5;9:*.tzo=38;5;9:*.t7z=38;5;9:*.zip=38;5;9:*.z=38;5;9:*.Z=38;5;9:*.dz=38;5;9:*.gz=38;5;9:*.lrz=38;5;9:*.lz=38;5;9:*.lzo=38;5;9:*.xz=38;5;9:*.bz2=38;5;9:*.bz=38;5;9:*.tbz=38;5;9:*.tbz2=38;5;9:*.tz=38;5;9:*.deb=38;5;9:*.rpm=38;5;9:*.jar=38;5;9:*.war=38;5;9:*.ear=38;5;9:*.sar=38;5;9:*.rar=38;5;9:*.alz=38;5;9:*.ace=38;5;9:*.zoo=38;5;9:*.cpio=38;5;9:*.7z=38;5;9:*.rz=38;5;9:*.cab=38;5;9:*.jpg=38;5;13:*.jpeg=38;5;13:*.gif=38;5;13:*.bmp=38;5;13:*.pbm=38;5;13:*.pgm=38;5;13:*.ppm=38;5;13:*.tga=38;5;13:*.xbm=38;5;13:*.xpm=38;5;13:*.tif=38;5;13:*.tiff=38;5;13:*.png=38;5;13:*.svg=38;5;13:*.svgz=38;5;13:*.mng=38;5;13:*.pcx=38;5;13:*.mov=38;5;13:*.mpg=38;5;13:*.mpeg=38;5;13:*.m2v=38;5;13:*.mkv=38;5;13:*.ogm=38;5;13:*.mp4=38;5;13:*.m4v=38;5;13:*.mp4v=38;5;13:*.vob=38;5;13:*.qt=38;5;13:*.nuv=38;5;13:*.wmv=38;5;13:*.asf=38;5;13:*.rm=38;5;13:*.rmvb=38;5;13:*.flc=38;5;13:*.avi=38;5;13:*.fli=38;5;13:*.flv=38;5;13:*.gl=38;5;13:*.dl=38;5;13:*.xcf=38;5;13:*.xwd=38;5;13:*.yuv=38;5;13:*.cgm=38;5;13:*.emf=38;5;13:*.axv=38;5;13:*.anx=38;5;13:*.ogv=38;5;13:*.ogx=38;5;13:*.aac=38;5;45:*.au=38;5;45:*.flac=38;5;45:*.mid=38;5;45:*.midi=38;5;45:*.mka=38;5;45:*.mp3=38;5;45:*.mpc=38;5;45:*.ogg=38;5;45:*.ra=38;5;45:*.wav=38;5;45:*.axa=38;5;45:*.oga=38;5;45:*.spx=38;5;45:*.xspf=38;5;45: SSH_AUTH_SOCK=/run/user/1000/keyring-QNL84t/ssh SESSION_MANAGER=local/unix:@/tmp/.ICE-unix/1240,unix/unix:/tmp/.ICE-unix/1240 USERNAME=mikhail PATH=/usr/local/bin:/usr/bin:/bin:/usr/local/sbin:/usr/sbin:/home/mikhail/.local/bin:/home/mikhail/bin MAIL=/var/spool/mail/mikhail DESKTOP_SESSION=gnome QT_IM_MODULE=ibus PWD=/home/mikhail/test XMODIFIERS=@im=ibus GNOME_KEYRING_PID=1236 LANG=en_US.utf8 GDM_LANG=en_US.utf8 GDMSESSION=gnome HISTCONTROL=ignoredups XDG_SEAT=seat0 HOME=/home/mikhail SHLVL=2 GNOME_DESKTOP_SESSION_ID=this-is-deprecated LOGNAME=mikhail DBUS_SESSION_BUS_ADDRESS=unix:abstract=/tmp/dbus-GFq7MYXuEF,guid=2967dcfefd00586db9916b58541820a3 LESSOPEN=||/usr/bin/lesspipe.sh %s WINDOWPATH=1 XDG_RUNTIME_DIR=/run/user/1000 DISPLAY=:0 COLORTERM=gnome-terminal XAUTHORITY=/run/gdm/auth-for-mikhail-8O9TTd/database _=/usr/bin/printenv [mikhail@localhost test]$ |
Если быть более точным, команда printenv выводит только список переменных окружения, а мы задали локальную переменную «TEST». Подробно о внутреннем устройствое переменных и работе с ними я напишу в материалах программирования и разработки скриптов для Linux Shell. Если есть желание увидеть список всех переменных сейчас, можно самостоятельно научиться работать с командой set. Мы ведь помним где получить справку по незнакомой команде? 🙂
Подстановка команд
Мы уже знаем как перенаправить вывод команды в файл или прицепить к вводу другой команды. А еще его можно подставить в строку и передавать как аргументы другой команды. Для развертывания вывода команды, саму команду необходимо обернуть в круглые скобки и поставить перед ними символ “$” (знак доллара). Посмотрим как это работает.
|
|
[mikhail@localhost test]$ ls bin.txt test1.txt test3300.txt usr-sorted.txt photo test2.txt test.txt usr.txt [mikhail@localhost test]$ echo $(ls) bin.txt photo test1.txt test2.txt test3300.txt test.txt usr-sorted.txt usr.txt [mikhail@localhost test]$ echo SPISOK: $(ls) SPISOK: bin.txt photo test1.txt test2.txt test3300.txt test.txt usr-sorted.txt usr.txt [mikhail@localhost test]$ |
Вместо знака доллара и скобок можно использовать символ «`» (обратная кавычка).
|
|
[mikhail@localhost test]$ echo SPISOK: $(ls) SPISOK: bin.txt photo test1.txt test2.txt test3300.txt test.txt usr-sorted.txt usr.txt [mikhail@localhost test]$ echo `ls` bin.txt photo test1.txt test2.txt test3300.txt test.txt usr-sorted.txt usr.txt [mikhail@localhost test]$ echo SPISOK: `ls` SPISOK: bin.txt photo test1.txt test2.txt test3300.txt test.txt usr-sorted.txt usr.txt [mikhail@localhost test]$ |
Данный функционал особо полезен при разработке Shell скриптов и его можно использовать совместно с переменными, записывая в них результат выполнения команд. Но об этом позже 🙂








